-数据库原理-数据CAP原理
高可用的数据
对于许多应用而言,数据是宝贵的,必须的资产。数据是整个应用的历史,是记录也有可能是配置信息,如果丢失了数据,那么对于某些应用来说结果可能就是毁灭性的,整个应用都有可能因此无法运行。
不同于高可用的应用或服务的设计方式,由于数据存储服务器上存储的数据不同,当某台服务器宕机之后,数据访问请求不能任意的切换到集群中其它数据服务器上。
CAP
CAP理论是分布式系统中对数据的管理而形成一套理论知识,CAP是设计分布式系统所必须考虑的架构问题。对于CAP本身可以解释如下:
- Consistency(一致性): 数据一致更新,所有数据变动都是同步的
- Availability(可用性): 好的响应性能
Partition tolerance(分区耐受性): 可靠性
上面的解释可能显得太过抽象,举例来说在高可用的网站架构中,对于数据基础提出了以下的要求:
分区耐受性
保证数据可持久存储,在各种情况下都不会出现数据丢失的问题。为了实现数据的持久性,不但需要在写入的时候保证数据能够持久存储,还需要能够将数据备份一个或多个副本,存放在不同的物理设备上,防止某个存储设备发生故障时,数据不会丢失。- 数据一致性
在数据有多份副本的情况下,如果网络、服务器、软件出现了故障,会导致部分副本写入失败。这就造成了多个副本之间的数据不一致,数据内容冲突。 数据可用性
多个副本分别存储于不同的物理设备的情况下,如果某个设备损坏,就需要从另一个数据存储设备上访问数据。如果这个过程不能很快完成,或者在完成的过程中需要停止终端用户访问数据,那么在切换存储设备的这段时间内,数据就是不可访问的。CAP原理认为,一个提供数据服务的存储系统无法同时完美的满足一致性(Consistency)、数据可用性(Availability)、分区耐受性(Partition Tolerance)这三个条件。对于三者的关系见图1.
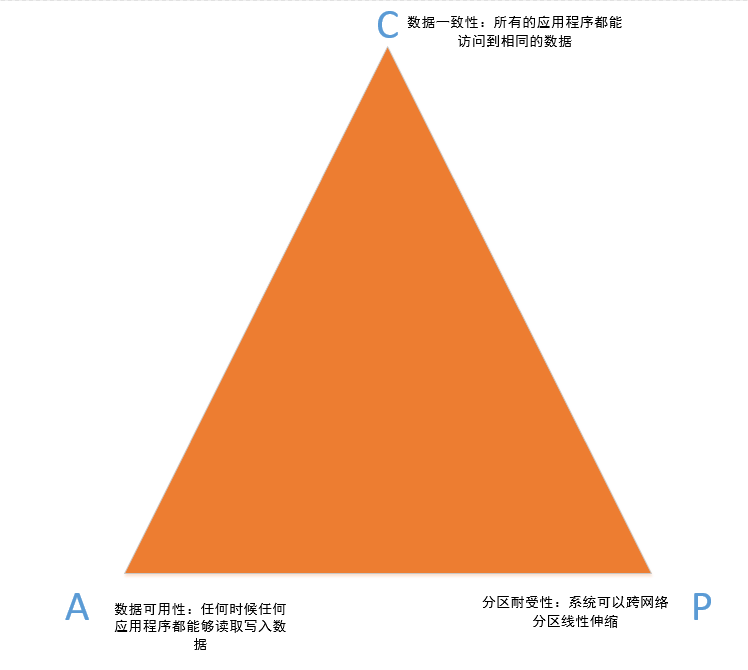
图1 CAP原理关系图
在实际的大型网络应用中,数据的规模会快速扩张,因此数据架构的伸缩性(分区耐受性)必不可少。当规模变大之后,机器的数量也会增大,这时网络和服务器故障会更频繁出现,想要保证应用可用,就必须保证分布式处理系统的高可用性。所以在大型网站中,通常会选择强化分布式存储系统的可用性(A)和伸缩性(P),在某种程度上放弃一致性(C)。一般来说,数据不一致的情况通常出现在高并发写操作或者集群状态不稳(故障恢复,集群扩容…)的情况下,应用系统需要对分布式数据处理系统的数据不一致性有一定的了解并进行某种意义上的补偿工作,以避免应用出现数据不正确。
CAP原理对于可伸缩的分布式系统设计具有重要的意义,在系统设计开发过程中,不恰当的迎合各种需求,企图打造一个完美的产品,可能会使设计进入两难之地,难以为继。
具体来说,数据一致性又可分为以下几点:- 数据强一致
各个副本中的数据总是强一致的。这种设计正确性很高,但是会在一定程度上损耗性能。 - 数据用户一致
应用访问数据时通过一定的纠错和校验机制,把多个数据可能不一致的副本的数据综合计算返回一个一致且确定的数据给用户。大型互联网架构一般采用这种设计,性能较好,并且数据不会出现错误。 数据最终一致
物理存储的数据不一致,用户访问得到的数据也可能不一致,但经过一段时间的自我修正(通常很短时间),数据会达到最终一致。该设计性能最高,但可能有数据错误。因为很难去同时满足CAP,大型网站通常会综合成本、技术、业务场景等条件,结合应用服务和其它的数据监控与纠错功能,使存储系统达到用户一致,保证用户最终访问数据的正确性。
20170804 18:10:00 编辑到多种数据一致性
引用
本文是对class文件的学习笔记,笔记的内容并非是原创,而是大量参考其它资料。在写作本文的过程中引用了以下资料,为为在此深深谢过以下资料的作者。
- 《大型网站技术架构·核心原理与案例分析》 李智慧 2013 电子工业出版社

